




.jpg)

Apriori Algorithm
Apriori algorithm is proposed by R. Agrawal and R Srikant in 1994 for mining frequent itemsets for boolean association rules. The algorithm uses prior knowledge of frequent itemsets properties hence the name Apriori. This alogorithm finds the frequent itemsets using candidaate generation.
Apriori-Process
- It is a two step process consisting of join and prune actions
- First, the setof frequent 1-itemsets is found by scanning the database to accumulate the count for each item, and collecting those items that satisfy minimum support and the The resulting set is denoted L1
- Next, L1 is used to find L2, the set of frequent 2-itemsets, which is used to find L3, and so on, until no more frequent k-itemsets can be found
- The finding of each Lk requires one full scan of the database
- Apriori property: All nonempty subsets of a frequent itemset must also be frequent
- TheApriori property is based on the following observation. By definition, if an itemset I does not satisfy the minimum support threshold, min sup, then I is not frequent; that is, P(I) < min sup
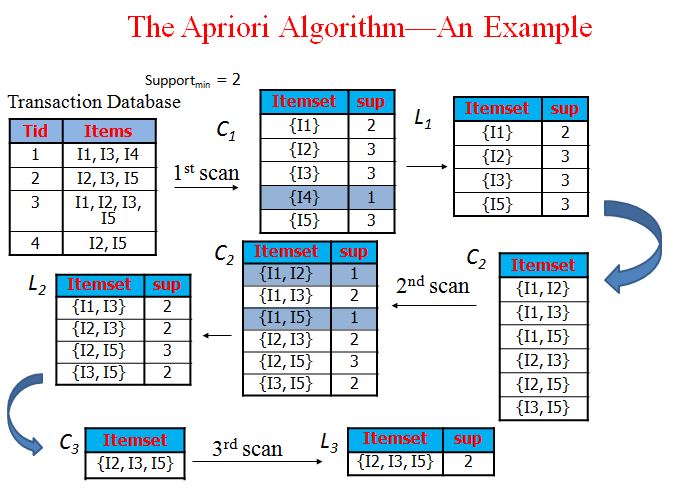
Thus the frequent pattern in the Transaction Database given is found out as I2, I3, I5 which is given in L3
Association Rules << Previous
Next >> Frequent Pattern growth
Reference: Data Mining Concepts and Techniques by Jiawei Han and Micheline Kambe
Our aim is to provide information to the knowledge seekers.






